


A Short History of Big Data
How much information, data explosion, storage expansion

The current version of “AI,” what used to be called “deep learning,” is a branch of machine learning that requires lots of data to succeed at what it does best: pattern recognition. Identifying specific patterns (correlations) in the data creates examples that allow the computer to “learn” to identify a word or an image or fraudulent online behavior and much more.
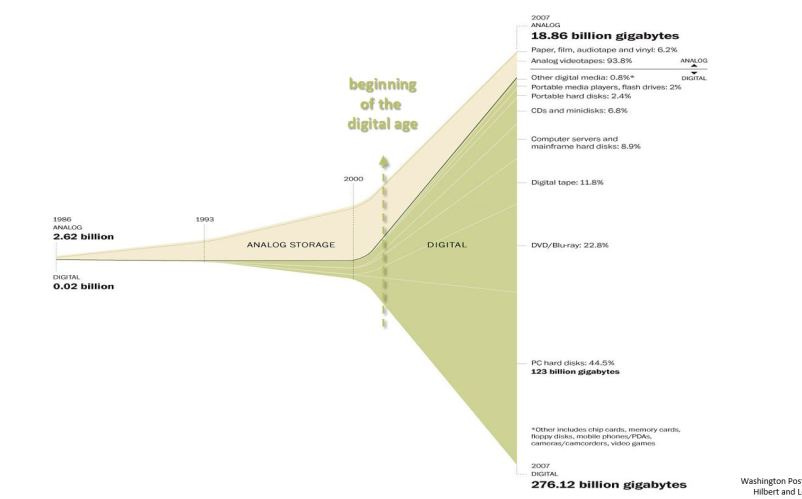
The Web, invented in 1989, has driven the rapid digitization of all types and forms of data. The introduction of the smartphone in 2007 further enabled the generation and sharing of new and large volumes of consumer-generated data. The information that used to be stored in non-digital containers such as books, microfilms, or photographs, was digitized, and new information was created as digital information. In 1986, 99.2% of all stored information was analog, but in 2007, 94% was digital, a complete reversal.1
The following is a brief history of the growth in the volume of data and information and the evolution of storing, organizing, accessing, and sharing it.
The term “information explosion” first appeared in 1941, according to the Oxford English Dictionary. At the time, this primarily meant data and information stored on paper or microfilm or analog images or analog audio recording media in file cabinets, libraries, and archives. In 1944, Fremont Rider, the Wesleyan University Librarian, published “The Scholar and the Future of the Research Library.” Rider estimated that American university libraries were doubling in size every sixteen years. Given this growth rate, Rider speculated that the Yale Library in 2040 will have “approximately 200,000,000 volumes, which will occupy over 6,000 miles of shelves… [requiring] a cataloging staff of over six thousand persons.”
The information explosion, then and now, gives rise to a familiar frustration—why can’t I find a particular piece of information or an answer to my question? In July 1945, Vannevar Bush published “As We May Think,” envisioning the “Memex,” a memory extension device serving as a large personal repository of information stored on microfilm that could be instantly retrieved via an associative link, similar to how the human mind operates. “Selection [i.e., information retrieval] by association, rather than by indexing, may yet be mechanized,” Bush wrote, anticipating how information is organized and found on the Web.
A few months later, in February 1946, the ENIAC, the first electronic general-purpose computer, was unveiled to the public. ENIAC and all the computers that came after it turned all data and information into 1s and 0s. For a while, however, tracking and quantifying the information explosion was still done in non-digital units such as the number of publications or words or hours.
In 1961, Derek Price traced the growth of scientific knowledge in Science Since Babylon by looking at the number of scientific journals and papers. Price concluded that the number of new journals has grown exponentially rather than linearly, doubling every fifteen years and increasing by a factor of ten during every half-century. In 1975, Japan’s Ministry of Posts and Telecommunications conducted its Information Flow Census for the first time, tracking the volume of information circulating in Japan, using “amount of words” as the unifying unit of measurement across all media types.
In 1983, Ithiel de Sola Pool applied the same methodology to the growth of 17 communications media in the U.S. from 1960 to 1977. Similar to the conclusions of the Japanese census, Pool found that information supply was increasing much faster than information consumption and that two-way personal communications were rapidly replacing one-way mass media (broadcasting). Adopting the same methodology in 2012, Neuman, Park, and Panek (in “Tracking the flow of information into the home”) estimated that the total media supply to U.S. homes has risen from around 50,000 minutes per day in 1960 to close to 900,000 in 2005. Looking at the ratio of supply to demand in 2005, they estimated that people in the U.S. are “approaching a thousand minutes of mediated content available for every minute available for consumption.”
Digital or computer-related measurements of information volumes appeared, starting in the 1980s, in new studies of “How Much Information?” These measurements of the storage capacity of computers—bits and bytes—arrived with the emergence of modern computing and were widely used in the computer industry.
In 1948, Claude Shannon published "A Mathematical Theory of Communication" in the July and October issues of the Bell System Technical Journal. Shannon wrote: “If the base 2 is used [for measuring information], the resulting units may be called binary digits, or more briefly bits, a word suggested by J. W. Tukey. A device with two stable positions, such as a relay or a flip-flop circuit, can store one bit of information.” A year later, Shannon listed the storage capacity in bits of several items in his notebook. He estimated that a punch card has just under 103 bits and a single-spaced typed page 104 bits. Four years before the discovery of the double-helix structure of DNA, Shannon estimated that the “genetic constitution of man” is about 105 bits. The largest holder of bits he could think of was the Library of Congress, which he estimated to hold 1014 bits of information.
Bits became the measurement of the power of computers, the size of their digital storage, and the status of their managers. “Too many information handlers seem to measure a man by the number of bits of storage capacity his dossier will occupy,” Arthur Miller wrote in The Assault on Privacy (1971). In 1980, at the Fourth IEEE Symposium on Mass Storage Systems, I.A. Tjomsland provided a great explanation of the data explosion: “Those associated with storage devices long ago realized that Parkinson’s First Law may be paraphrased to describe our industry—‘Data expands to fill the space available’…. I believe that large amounts of data are being retained because users have no way of identifying obsolete data; the penalties for storing obsolete data are less apparent than are the penalties for discarding potentially useful data.”
In 1982, the Hungarian Central Statistics Office started a research project to account for the country’s information output by measuring information in bits for digital products and for non-digital products, “as if digitized.” In 1997, Michael Lesk published “How much information is there in the world?” Lesk concluded that “there may be a few thousand petabytes of information all told; and the production of tape and disk will reach that level by the year 2000. So in only a few years, (a) we will be able [to] save everything–no information will have to be thrown out, and (b) the typical piece of information will never be looked at by a human being.” Lesk estimated the size of the Library of Congress to be 3 petabytes (27,021,597,764,222,970 bits).
In October 2000, Peter Lyman and Hal R. Varian at UC Berkeley published How Much Information?, the first comprehensive study to quantify, in computer storage terms, the total amount of new and original information (not counting copies) created in the world annually and stored in four physical media: paper, film, optical (CDs and DVDs), and magnetic (disks and tapes). The study found that the world produced about 1.5 exabytes (1.5 billion gigabytes) of unique information in 1999. It also found that “a vast amount of unique information is created and stored by individuals” (what it called the “democratization of data”) and that “not only is digital information production the largest in total, it is also the most rapidly growing.” Calling this finding “dominance of digital,” Lyman and Varian stated, "Even today, most textual information is ‘born digital,’ and within a few years, this will be true for images as well.” A similar study conducted in 2003 by the same researchers found that the world produced about 5 exabytes of new information in 2002 and that 92% of the new information was stored on magnetic media, mostly in hard disks.
In March 2007, John F. Gantz, David Reinsel, and other researchers at IDC released a white paper titled “The Expanding Digital Universe: A Forecast of Worldwide Information Growth through 2010.” It was the first study to estimate and forecast the amount of digital data created and replicated annually worldwide. IDC estimated that in 2006, the world created 161 exabytes of data and predicted that between 2006 and 2010, the information added annually to the “digital universe” will increase more than sixfold to 988 exabytes, or doubling every 18 months. According to the 2010 and 2012 releases of the same study, the amount of digital data created annually surpassed the forecast, reaching 1,227 exabytes in 2010 and growing to 2,837 exabytes in 2012. The most recent edition of this study estimated that the world created and copied 149 zettabytes (149,000 exabytes) in 2024.
Digital storage became more cost-effective for storing data than paper in 1996.2 The world was ready for a new term to capture the data explosion.
In October 1997, in the Proceedings of the IEEE 8th Conference on Visualization, the term “Big Data” appeared for the first time in a computer science publication. Michael Cox and David Ellsworth wrote: “Visualization provides an interesting challenge for computer systems: data sets are generally quite large, taxing the capacities of main memory, local disk, and even remote disk. We call this the problem of big data.” The term caught on in the computer industry—for example, in April 1998, John R. Mashey, Chief Scientist at SGI, a developer of high-end graphics workstations, presented at a USENIX meeting a paper titled “Big Data… and the Next Wave of Infrastress.”3
In subsequent years, Cox and Ellsworth and other computer science researchers continued to explore the challenges associated with managing large datasets “in the range of 300 gigabytes,” resulting from calculations by supercomputers and scientific simulations. The visualizations required by increasingly sophisticated computer games also played a significant role in the rise of Big Data. Quite a few startups were launched in the 1990s to develop and sell innovative add-on 3D graphics cards. In 1999, NVIDIA introduced what it called “the world’s first GPU,” a specialized chip that helped deep learning triumph in 2012 over all other approaches to artificial intelligence.
Big Data soon graduated from computer games to basically everywhere. In November 2000, Francis X. Diebold told the Eighth World Congress of the Econometric Society, “Recently, much good science, whether physical, biological, or social, has been forced to confront—and has often benefited from—the ‘Big Data’ phenomenon. Big Data refers to the explosion in the quantity (and sometimes, quality) of available and potentially relevant data, largely the result of recent and unprecedented advancements in data recording and storage technology.”
Big data was further established as a major driver of modern science and other endeavors in 2008 with the publication of a special issue (September) of Nature examining “what big data sets mean for contemporary science." Randal E. Bryant, Randy H. Katz, and Edward D. Lazowska followed in December with “Big-Data Computing: Creating Revolutionary Breakthroughs in Commerce, Science and Society”: “Just as search engines have transformed how we access information, other forms of big-data computing can and will transform the activities of companies, scientific researchers, medical practitioners, and our nation’s defense and intelligence operations…. Big-data computing is perhaps the biggest innovation in computing in the last decade.”
In February 2010, Kenneth Cukier (one of the world’s first “data journalists”) published in The Economist a special report titled, “Data, data everywhere.” Cukier wrote: “…the world contains an unimaginably vast amount of digital information which is getting ever vaster more rapidly… The effect is being felt everywhere, from business to science, from governments to the arts. Scientists and computer engineers have coined a new term for the phenomenon: ‘big data.’”
The McKinsey Global Institute published in May 2011 “Big Data: The Next Frontier for Innovation, Competition, and Productivity,” estimating that “by 2009, nearly all sectors in the US economy had at least an average of 200 terabytes of stored data (twice the size of US retailer Wal-Mart’s data warehouse in 1999) per company with more than 1,000 employees” and that the securities and investment services sector leads in terms of stored data per firm. In total, the study estimated that 7.4 exabytes of new data were stored by enterprises and 6.8 exabytes by consumers in 2010.
On February 24, 2016, PBS released a new documentary, “The Human Face of Big Data.” PBS’s press release stated, “The era of Big Data is an important inflection point in human history and represents a critical moment in our civilization’s development.”
This was probably the greatest missed/failed timing in the history of over-hyped terms and technology-driven bubbles. By 2016, “Big Data” was replaced by “AI” as the “new new thing” that was going “to change everything,” Silicon Valley’s reality-denying mantra.
Martin Hilbert and Priscila Lopez, “The World’s Technological Capacity to Store, Communicate, and Compute Information,” Science, February 2011.
R.J.T. Morris and B.J. Truskowski, in “The Evolution of Storage Systems,” IBM Systems Journal, July 1, 2003.
In 2013, The Oxford English Dictionary added the term Big Data, defining it as “data of a very large size, typically to the extent that its manipulation and management present significant logistical challenges.” Unfortunately, it suggested that the earliest use of the term was by sociologist Charles Tilly, writing in a 1980 working paper surveying “The old new social history and the new old social history” that “none of the big questions has actually yielded to the bludgeoning of the big-data people.” While the context is the increasing use of computer technology and statistical methods by historians, it is clear that Tilly used the term not to describe specifically the magnitude of the data or the “logistical challenges” of its management but as a flourish of the pen following the words “big questions.” The meaning of the sentence would not change if he used only the word “data.”